
인공신경망을 학습시키는 과정과 경하 하강 알고리즘에 대해서 알아 보겠습니다
우리는 어떻게 인공신경망을 학습 시킬까요?
우리는 멀티 레이어 퍼셉트론 네트워크를 구축하는 방법에 대해 배웠고
기본적으로 행렬이라는 것을 배웠죠
그리고 여기에서 최적의 가중치 값을 찾아봤어요
그럼 이제 실제 학습 과정으로 가봅시다

여기 이 네트워크가 있죠
이 네트워크는 학습이 안된 상태라고 가정해 봅시다
방금 가중치들을 무작위로 초기 설정해 줬어요
여기의 모든 무게 값들은 아무 의미도 없어요 그냥 랜덤 숫자 무더기들이죠
그리고 나서, 우리의 데이터를 가지고 나눠볼 거예요
제가 전에 언급했듯이, 학습과 테스트로요
이 학습 데이터들은 여기 있는 모델에 입력해줄 것이고
그리고 보통, 트레이닝 데이터의 모든 입력들에 대해 대응하는 라벨이 있어요
예를 들어, 입력과 출력이 있죠
전에 예시에서는 이미지와 그에 상응하는 주요 얼굴 포인트들이 있죠
그러면, 이제 모든 이미지들에 각각 해당하는 관련된 라벨이 있는 것이죠

자, 이게 입력 값 X이고요

이것을 예상하는(실제) 출력 값 Y라고 부릅니다
그리고 여기에서 일어날 일은, 처음에 학습되지 않은 상태에서도 출력을 만들어 낼 거예요
예측 결과를 만들어 낼 것이에요
그리고 이 예측 결과를 ^y 이라고 부를 거랍니다
기본적으로 이 예측은 엉터리 값이에요
왜냐하면 여기에 실린 가중치들은 모두 무작위로 적혔기 때문이죠
아무 의미가 없어요
우리가 할 것은 에러 신호를 계산하는 것인데
모델 예측 값(^y)와 예상한 실제 값(y)의 차를 구하는 것이에요
왜냐고요?
에러 신호를 계산한 다음 네트워크 가중치를 갱신해 줄 것이에요
그리고, 인간과 비슷하게 인공 신경망은 이 경험으로 배워요
예시들로 배우고, 시간이 흐를 수록 계속해서 배울 거예요
그래서, 우리는 이 모든 데이터들을 이 네트워크에게 계속 반복하고, 반복해서 보여줘야하죠

여기 보시다시피 다중 에폭스라고 부릅니다
그래서, 처음에는 굉장히 큰 에러로 시작하지만
계속해서 반복하고 반복해서 이 에러가 줄어들기 시작하고,
계속 줄어들고 줄어드는 것을 것을 보실 수 있으실 거예요
그리고 모델이 완전히 학습된 상태까지 도달하면
에러는 거의 0에 수렴할 것이고 모델의 예측 결과가 이미 예상한 실제 출력 값과
동일하다는 뜻이죠
특히 AI를 처음 공부하시는 분들에게는 특별히 더 중요한 부분이에요
이렇게 모델을 학습시킨 다음엔 이제 모델을 테스트해볼 거예요

그래서 이 네트워크를 가져오고 가져오고 가중치들을 고정시켜요
이 모든 가중치들은 이제 변하지 않아요
그리고 이제 가져올 수 있고, 테스트 데이터를 이용해서 모델 성능을 테스트해볼 수 있어요
그리고 참고로, 이 테스트 데이터는 이 모델이 학습을 할 동안에 한번도 본 적이 없는 데이터예요
자, 이제 테스트 데이터를 가지고 와서 이 네트워크에 주면 이제 새로운 예측 결과를 만들어 내겠죠
그 후에는, 그 모델을 가져와서 핸드폰이나 엣지, 혹은 자동차같은 곳에
배포할 수 있고 그리고 그 모델이 한번도 본적 없는 새로운 이미지들로 테스트 해볼 수 있는 것이죠
이것이 일반적으로 AI 모델을 학습시키고 테스트하는 과정을 포괄적으로 설명한 것이에요
그리고 여기에서 해볼 것은 저는 여기에 2가지 전략이 있어요

그래서, 첫 번째는 모든 데이터를 가져와서 학습과 테스트로 나누는 것이에요
대부분을 80 퍼센트로 학습과 20 퍼센트의 테스트로 나누었죠
그리고, 다시 강조하지만 테스트 데이터는 모델이 학습하는 동안 본적이 없는 처음보는 데이터예요
이 점이 매우 중요해요 이게 한 가지 방법이고요
두 번째 전략은 데이터를 세 덩어리로 나누는 거예요
첫 번째 것은 학습 데이터로 총 데이터의 60 퍼센트가 될 것이고
그리고 20 퍼센트를 검증데이터에 그리고 20 퍼센트를 테스트 데이터로 나누어 줄거예요
학습 데이터와 테스트 데이터가 무엇인지는 알고 있고
유효 데이터 세트는 뭘까요?
우리가 하고자 하는 것은 모델을 학습시킬 때 이 모델들이 일반화할 수 있도록 해주는 거예요
그리고 학습 데이터에 과적합하지 않도록 해줄 거예요

기본적으로, 네트워크가 학습될 때 여기보면 에러는 줄어들고
모델은 학습 데이터를 너무 과하게 배우지 않아요
그 말은 즉, 저는 모델이 제 데이터 속 모든 입력과 출력,
데이터의 모든 비선형(non-linearity)를 배우는 것을 원하지 않아요
그저 이 이미지에 대해서 잘 작동하기만을 원하죠
왜냐하면 실습에서 다른 이미지들을 보게될 것이에요
저는 이 모델이 학습데이터에서만 잘 작동하고, 다른 데이터에서는
엉망으로 작동하는 것을 원하지 않아요
그래서 검증 데이터세트를 나누어 놓는 것이고 모든 에폭마다 모델이 학습할 때
우리는 모델이 한 번도 보지 못한, 새로운 데이터세트로 실행시킬 것인데
이게 검증 데이터세트예요
학습 데이터에 대한 에러가 내려가고 검증데이터에 대한 에러가
내려갈 때까지 실행합니다
만약 둘다 내려간다면, 좋은 신호네요
그 말은 이제 모델이 일반화할 수 있다는 뜻이니까요
하지만, 만약 학습 데이터에 대한 오류는 줄어들고, 유효 데이터에 대한 오류는
늘어난다면 그 뜻은
모델이 학습 데이터를 과도하게 학습하기 시작한 것이에요
이제, 모델이 기본적으로 학습 데이터의 디테일까지도 학습하는게 가능하다 보니까 일반화를
실패하는 것이에요
그리고, 우리는 무슨 수를 써서라도 그렇게 되질 않길 원하죠
그리고 학습을 멈출 거예요
"학습을 중단하고 더이상 학습시키지 않을 거예요
지금이 좋습니다" 라고요
그리고, 검증데이터는 학습 과정에서 사용한다는 것을 유념해주세요
그리고 모델이 학습 된 다음에는 테스트 데이터를 이용해서 테스트하면 됩니다

자, 경사 하강 알고리즘에 대해 다뤄 봅시다
그리고 기본적으로 우리가 하려는 것은 최적의 네트워크 가중치를 찾으려고 하는 거예요
그게 제가 원하는 것이죠
에러를 최소화하는 최고의 가중치를 찾을 거예요
그리고 이 인공신경망을 학습시킬 때 '경사하강 알고리즘'이라는 기술을 써볼 거예요

기본적으로, 여기에 있는 것은 에러 곡선이에요
자, 초기 네트워크 가중치를 무작위로 설정했다고 가정하고

한 여기쯤에서 시작을 했다고 해봅시다
그럼 에러는 정말 높죠
그리고 저는 계속해서 감소시키려고 할것이고
최소 지점을 찾으려고 해보겠죠
전체적인 오류를 최소화하는 네트워크 가중치 값을 찾고자 하는 것입니다
최소값을 찾는 거예요 그리고 이럴 때 '경사하강법'이라는 것이 사용돼요
저는 아무 곳에서 첫 기울기를 계산할 것이고 기울기가 감소하는 방향으로
가도록 할 겁니다
계속 내려가는 것이죠. 계속 해서 내려가면 그건 좋은 거예요
최소 포인트를 찾고 있다는 뜻이니까요
그리고 최소 포인트까지 닿으면 최적의 가중치 값을 찾은 거예요
이것이 기본적으로 최적화를 하고자 할 때에 우리가 하는 일이에요
이 지점과 가중치 값을 찾고, 즉, 파라미터 값을 찾아서 전체적인 에러를
최소화하는 것이죠
자, 경사 하강 알고리즘은 최적화 알고리즘으로서, 최적의 네트워크 가중치와 바이어스 값을
찾는데에 사용돼요
반복적으로 비용함수를 최소화하려고 하는 방식이죠
비용함수의 기울기를 계산하는 방식으로 작동하고
우리는 아무 곳에나 기울기를 계산하고 로컬 또는 글로벌 최소값에 닿을 때 까지
감소하는 방향으로 가는 것이에요
그리고, 기본적으로 만약 양수의 기울기를 사용하고 싶으시다면, 감소시키는 것이 아니라
상승시키게 될 것이고 로컬 또는 글로벌 최대값을 얻게 될 거예요
그리고, 우리가 이런 모델들을 학습시킬 때 '학습률'이라는 것을 사용해요
기억하신다면, 우리 네트워크를 학습시켜 볼 때 다뤄 봤었는데요

기억해 보시면 학습률이 있었고 선택할 수 있었어요
이것은 얼마나 적극적으로 감소시키고 싶은지를 정하는 것이에요
정말 빠르게, 적극적으로 감소시키고 싶은지 아니면 천천히
아주 천천히 아래를 향해서 가고 싶은지 말이에요
이 학습률이 상승하면 탐색 공간도 넓어지는데요
빠르게 감소하는 뜻이에요 아래로 내려가서 더 적극적으로 가중치를 찾는 것이죠
더 빠르게 최소값에 닿게 되긴 할거예요
하지만 이렇게 하면 목표를 지나버릴 수도 있다는 문제가 있어요
예를 들어, 제가 찾고자 하는 지점이 여기인데 너무 빠르게 감소해서
실제로 제 글로벌 최소값 제가 원하는 지점을 지나쳐버리는 것이죠
하지만, 반대로 정말 작은 학습률을 설정하면, 글로벌 최소값에 도달하기까지
영원히 걸릴 거예요
지점에 닿을 때 까지 정말 정말 느리게 움직일 거예요
조금 더 깊이 들어가서 수학을 조금 봅시다

y = b + m*x라는 직선방정식이 있다고 가정해 봅시다
x는 독립 변수이고요 y는 종속 변수예요
제가 가지고 있는 것은 b와 m, 두가지 매개변수 뿐이에요, 그리고 매개변수를 최적화시켜 볼거예요
그게 제가 하고자하는 것이죠

그래서 이제 학습데이터를 달라고 할거예요
데이터가 필요합니다 그래서 x, y 데이터를 수집할거고 모델을 학습시는 시켜 볼 거예요
그래서, 여기서 해볼 것은 모델이 초기에 예측, 예측값을 만들어 내겠죠
그리고 그 값은 ^y가 될 거예요
그리고 뺄셈을 해볼 것인데 모델의 예측 값 - 원본 데이터를 해줄 거예요
제가 원하는 사실 라벨이죠 즉 '^y - y'을 해줄 것이고
이게 에러 신호가 될거예요
그리고 이 에러신호를 다시 가지고 가서, 네트워크의 매개변수인 m과 b를
업데이트 해줄 거예요

여기에서 해볼 것은 비용함수라고 부르는 것을 만들 거예요
비용함수는 우리가 최소화 시키고자 하는 함수예요
최대한 최소화 해줄 것이죠
그리고 이 사례에서 비용 함수는 이렇게 골라줄 거예요
에러인 ^y을 선택해줄 것이고 여기에서 만든 모델 예측 결과이죠
그리고, 빼기 y(i) 이건 실제의 출력(ground-truth)이죠
기반 사실이에요
이제, 모델 예측 결과 - 기반 사실을 해주고 제곱을 해줄 거예요

이게 제곱이라는 뜻이고
제곱을 하는 이유는 부호를 지우기 위해서예요 여기가 0이던 양수이든 음수이든
중요하지 않아요
그냥 제곱을 해줘서 부호를 지워줄 거예요
그 다음 모두 더해줄 것이고 즉, 학습 데이터의 모든 곳의 에러들을 다 더해줄 것이예요
10곳이 있다면 10곳 모두 에러를 더해줄 거예요
그리고 난 다음, 전체 샘플 개수인 N으로 나누어 줄거예요
그리고, 이게 기본적으로 우리가 칭하는 비용 함수라는 것이에요
즉, 에러 값들의 제곱의 합이라고 할 수 있죠
그리고 이제 남은 것은 최대한 에러를 줄이도록 최적의 m과 b를 찾는 거예요
저는 이제 함수를 찾았고, 최소화 하기만 하면 됩니다
실제로 함수의 최소 값을 찾아보세요
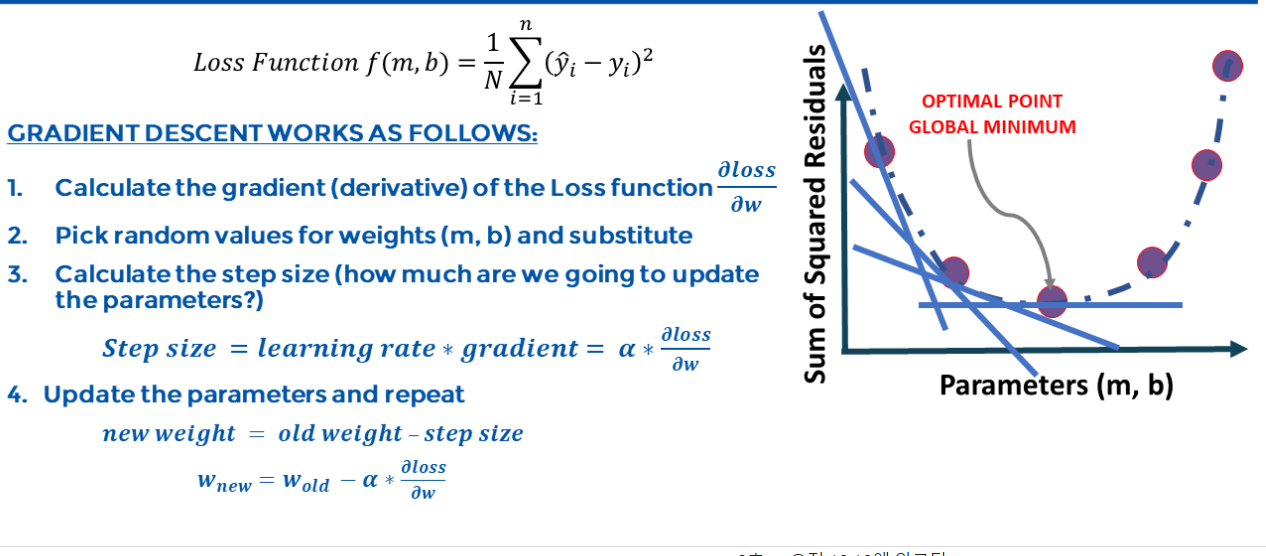
그리고 이게 경사하강 알고리즘을 사용할 때 하는 과정입니다
다시 돌아가서 이 손실함수, 혹은 비용함수라고 부르는 것을 구하고

그리고 여기서 시작한다고 가정해 봅시다

여기 y축은 뺄셈 값의 제곱의 합이고
이 뺄셈 값을 에러라고 생각하세요 이제 에러 값의 제곱의 합이 있죠
그리고 여기에는 b와 m 매개변수의 모든 조합들이 있어요
예를 들어, m과 b는 각각 1, 2라던지 4, 5 이렇게 아무 것이나 될 수 있죠

첫 번째로 우리는 손실함수를 구해볼 거예요, 여기 있죠
두 번째, 이 손실함수의 기울기 즉, 도함수를 계산해볼 거예요
가중치에 대한 손실함수의 편미분을 한다고 표현 할게요
가중치라고 하는 것은 m과 b를 말하는 것이고 아무 값이나 될 수 있어요
자, 그래서 먼저 도함수를 구해 볼게요이게 첫 번째 단계에요
그 다음, 두 번째 단계 랜덤한 값을 골라서 각각 m과 b에 대입해 줄게요
그리고 나서, 방금 계산한 기울기를 가지고 학습률과 곱해줍니다
그리고 제가 말씀드렸다시피, 학습률은 얼마나 적극적으로 가중치를 업데이트하고 싶은지를 뜻해요
예를 들어, 기울기를 구한 2를 곱해줄게요
그 말은, 지금 학습률을 높이는 것이죠
기울기를 가져와서 숫자를 곱해주는 거예요
2를 곱하고, 또는 1.5를 곱하고 이런 식으로요
반면에, 기울기를 완만하게 할 수도 있죠
예를 들어, 0.1, 0.01이렇게 곱해주는 것이죠
이게 학습률이에요

그러면 스텝 사이즈가 나올 거예요
스텝 사이즈를 구한 다음에는 그것을 가지고 와서
이전 매개변수, 이전 가중치로 빼서 새로운 가중치,
새로운 매개변수를 구하는 겁니다

그리고 이것이 기본적으로 이 알고리즘이 작동하는 방식이에요

매번마다, 여기에서 시작해서, 기울기를 구하죠
그리고, 그 기울기를 학습률과 곱해서
이전 가중치 매개변수로 빼주면
새로운 가중치 매개변수를 얻는 것이죠
그다음엔, 이 부분으로 내려올 것이고 다시 기울기를 구하고
똑같은 일을 반복하는 것이죠 기울기를 구하고, 학습률을 곱해서
새로운 매개변수를 얻고 이 일을 에러 제곱의 합이 최소가 되는 지점에 갈 때까지
계속 반복하고 반복해 주는 것이에요
그리고, 이것이 포괄적으로 경사하강 알고리즘이 작동하는 방식이죠
이에 대한 수많은 수학들이 있다는 것을 알아주세요
이것은 개략적으로 직관을 드리는 거예요
경사 하강법과 관련된 계산에 대해 더 자세히 알고싶으신 분들은
더 읽어보시기를 추천드려요
이제, 미니 과제를 할 시간이네요
만약 학습률이 극단적인 값이 되면 어떻게 되는지 알려주세요
매우 작은 값이거나, 매우 큰 값이면 어떻게 되는지 사실 이미 다룬 내용입니다
하지만 미니 과제에서 어떻게해야 두 가지 장점 모두 이용할 수 있는지
이 두 사이를 어떻게 조절할 수 있는지에 대해서도 생각해 볼 거예요
이를 위한 많은 기술들이 있죠
https://machinelearningmastery.com/understand-the-dynamics-of-learning-rate-on-deep-learning-neural-networks/
이 링크를 클릭하시면, Jason Brownlee가 적은 아주 좋은 기사가 있답니다
이것을 읽어보면, 학습률과 실제 학습률의 영향에 대해서 이야기 하고 있는데요
학습률이, 새로운 인공지능을 학습시키는데에 있어서, 가장 중요한 파라미터라고
이야기 하고 있어요
만약 아주 작은 학습률을 사용하면 학습을 완료할 때까지 정말 오래 걸릴 것이고
반대로 너무 높으면, 목표지점 즉, 글로벌 최소 지점을 넘어서서
불안정한 학습을 하는 것이죠, 왜냐하면 학습률을 너무 높이면
원하는 데이터 지점을 지나칠 것이니까요
그래서, 이를 막기 위해 적응형 학습률을 사용할 수 있어요
즉, 실제로 학습률을 바꿀 수 있고 곡선 위의 위치에 따라서 조절할 수 있는 것이죠
예를 들어, 여기보면, 시작할 때에는 아주 큰 학습률을 적용해서 빠르게 이동하도록 해주었죠
점점 글로벌 최소 지점에 가까워지면 학습률을 낮춰 주었고
그래서 특정 지점에서 적절히 조절할 수 있었어요
이것이 기본적으로
적응형 학습률을 이용해서 두가지 장점을 살리는 방법이에요
그리고, 다른 방법들도 많으니
여러분들이 이걸 꼭 읽어보시길 추천드려요 정말 흥미로운 내용들이 많거든요
'딥러닝' 카테고리의 다른 글
| 감정Ai(9)-RestNet을 만들어 얼굴 주요 특징점 검출하기 (0) | 2023.05.03 |
|---|---|
| 감정Ai(7)-합성곱 신경망과 ResNets 이해하기 (0) | 2023.05.03 |
| 감정Ai(5)-인공신경망(ANNs) 이론과 직감 이해하기 (0) | 2023.05.03 |
| 감정Ai(4)-데이터 일반화와 스케일링 수행하기 (0) | 2023.05.03 |
| 감정Ai(3)-이미지 증강하기, 밝기조절, 뒤집기 (0) | 2023.05.03 |



