[논문 번역] StackGAN: 텍스트를 실사 합성 이미지로 변환 (2017)
원문원본StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks)
윤효창 번역 실시 2023.01.17

논문 초록
텍스트 설명문을 고화질 이미지로 합성하는 것은 컴퓨터 비전에서 도전적인 과제임과 동시에 실제로 많은 분야에 적용할 수 있습니다. 기존의 text-to-image 접근법으로 생성된 샘플은 주어진 글의 의미를 대략적으로 반영할 수 있지만 중요한 디테일을 놓치거나, 선명하게 객체 부분 묘사를 하지 못합니다. 이 논문에서는 Stacked Generative Adversarial Networks (StackGAN)을 제안하여, 텍스트 설명문을 조건으로 256×256 사이즈의 실사 이미지를 생성합니다. 우리는 “스케치 개선 프로세스”를 통해 어려운 문제를 보다 관리하기 쉬운 하위 문제로 분해했습니다. Stage-I GAN은 주어진 텍스트 설명을 기반으로 객체의 원시 모양과 색상을 스케치하여 Stage-I 저해상도 이미지를 생성합니다. Stage-II GAN은 Stage-I의 결과와 텍스트의 설명을 입력으로 하고, 실사와 같은 디테일의 고해상도 이미지를 생성합니다. 이 단계에서 Stage-I 결과의 결함을 수정하고, 개선 프로세스를 통해 설득력 있는 세부 정보를 추가할 수 있도록 합니다. 또한, 합성된 이미지의 다양성을 향상시키고 conditional-GAN의 훈련을 안정화하기 위해, “latent conditioning 매니폴드”가 더 스무스함을 갖도록 새로운 “Conditioning Augmentation” 테크닉을 소개합니다. 벤치마크 데이터셋의 최신기술에 대한 광범위한 실험과 비교를 통해, 이 제안된 방법이 주어진 설명문을 기반으로 실사와 같은 이미지를 생성해내는데 있어서 엄청난 향상을 이뤄냈음을 확인했습니다.
1. 서론
하지만, 고해상도 실사같은 이미지를 텍스트 설명문으로부터 생성해내는 것은 매우 어려운 일이었죠. 고해상도 이미지를 얻겠다고 단순히 더 많은 upsampling 층을 최신 GAN 모델들에 추가하는 것은 훈련에 있어서 불안정성을 초래했고, 무의미한 결과물만을 생성해냈습니다 (Figure 1(c) 참조). GAN 모델을 이용해서 고해상도 이미지를 생성하는데 가장 큰 난관은 자연 이미지와 암시 모델의 분포의 토대가 고차원 픽셀 공간에서 겹치지 않을 수 있다는 것입니다[31, 1]. 이 문제는 이미지 해상도가 올라갈 수록 더 심각합니다. Reed et al. 은 그저 텍스트 설명문을 조건으로 그럴싸한 64x64 이미지를 생성하는 것만 성공했습니다[26]. 그것마저도, 예를 들어, 그냥 새의 부리와 눈만 있는 것처럼 세부적인 묘사와 이미지의 선명함은 빠져있는게 흔했습니다. 게다가, 객체에 대한 주석을 추가하지 않고서는 고해상도 이미지 합성(예: 128x128)[24]은 불가능합니다.

또한, text-to-image 생성 작업의 경우, 제한된 수의 text-to-image 쌍을 훈련시키는 것은 종종 텍스트 조절 매니폴드에 희소성을 초래하며 이러한 희소성은 GAN을 훈련시키는 것을 어렵게 만듭니다. 따라서, 우리는 잠재 컨디셔닝 매니폴드의 부드러움을 장려하기 위해 새로운 컨디셔닝 증강(Conditioning Augmentation) 기술을 제안합니다. 이 기술은 조건부 매니폴드에서 작은 임의 섭동(random perturbations, 랜덤한 노이즈)를 허용하고 합성 이미지의 다양성을 증가시킵니다.
제안된 방법이 기여하는 부분은 세 단계로 나뉘어집니다. (1) 텍스트 설명에서 사실적인 사진 이미지를 합성하기 위한 새로운 스택 생성 적대 네트워크(Stacked Generative Adversarial Networks)를 제안합니다. 이것은 고해상도 이미지 생성의 어려운 문제를 보다 관리하기 쉬운 하위 문제로 분해하여 최첨단 기술을 대폭 개선합니다. StackGAN은 먼저 256×256 해상도의 이미지를 텍스트 설명에서 사실적인 디테일로 생성합니다. (2) 조건부 GAN 훈련을 안정화하고 생성된 샘플의 다양성을 개선하기 위해 새로운 Conditioning Augmentation 기법을 제안합니다. (3) 광범위한 정성적, 정량적 실험은 개별 구성요소의 효과뿐만 아니라 전체 모델 설계의 효과도 입증합니다. 이 개별 구성요소는 앞으로의 조건부 GAN 모델 설계에 유용한 정보를 제공하게 됩니다. https://github.com/hanzhanggit/StackGAN 에서 우리 코드를 확인할 수 있습니다.
2. 관련 연구
하지만 이러한 생성 모델을 기반으로 조건부 이미지 생성도 연구되었습니다. 대부분의 방법에서는 속성 또는 클래스 레이블과 같은 단순한 조건부 변수를 사용했습니다[37, 34, 4, 22]. 이러한 생성 모델을 기반으로 조건부 이미지 생성도 연구되었습니다. 대부분의 방법에서는 속성 또는 클래스 레이블과 같은 단순한 조건화 변수를 사용했습니다. 또한 사진 편집[2, 39], 도메인 전송[32, 12] 및 초해상도[31, 15]를 포함하여 이미지를 생성하기 위해 이미지를 조절하는 작업도 있습니다. 그러나 초해상도 방법[31, 15]은 저해상도 이미지에 제한된 세부 정보만 추가할 수 있으며 우리가 제안하는 StackGAN처럼 큰 결함을 수정할 수 없습니다. 최근에는 비정형 텍스트에서 이미지를 생성하는 여러 방법이 개발되었습니다. Mansimov et al. [17]은 텍스트와 생성 캔버스 사이의 정렬을 추정하는 방법을 배워 AlignDRAW 모델을 구축했습니다. Reed et al. [27]은 조건부 PixelCNN을 사용하여 텍스트 설명 및 개체 위치 제약 조건을 사용하여 이미지를 생성합니다. Nguyen et al. [20]은 대략적인 Langevin 샘플링 방식을 사용하여 텍스트 조건부 이미지를 생성합니다. 그러나 표본 추출 방식에는 비효율적으로 최적화 프로세스를 반복하도록 합니다. 조건부 GAN을 통해 Reed et al. [26]은 텍스트 설명을 기반으로 새와 꽃에 대해 그럴싸한 64×64 이미지를 성공적으로 생성했습니다. 후속 작업[24]에서는 개체 부분의 위치에 대한 추가 주석을 활용하여 128×128개의 이미지를 생성할 수 있었습니다.
영상 생성을 위해 단일 GAN을 사용하는 것 외에도 영상 생성을 위해 여러개의 GAN을 연결해 사용한 작업도 있습니다[36, 5, 10]. Wang et al. [36]은 제안된 �2S2-GAN으로 실내 장면 생성 프로세스를 구조 생성 및 스타일 생성으로 인수분해했습니다. 이와는 대조적으로, StackGAN의 두 번째 단계는 텍스트 설명을 기반으로 객체 디테일을 완성하고 Stage-I 결과의 결점을 수정하는 것을 목표로 합니다. Denton et al. [5]은 Laplacian 피라미드 프레임워크 내에 일련의 여러 GAN을 구축했습니다. 피라미드의 각 레벨에서 이전 단계의 이미지에 따라 잔여 이미지가 생성된 후 입력 이미지에 다시 추가되어 다음 단계의 입력을 생성합니다. 또한 Huang et al. [10] 은 우리의 작업과 동시에 여러 GAN을 쌓아서 사전 훈련된 분별 모델의 다단계 표현을 재구성함으로써 더 나은 이미지를 생성할 수 있음을 보여주었습니다. 그러나 그들이 32×32 크기의 이미지 생성에만 성공한 반면, 우리의 방법은 보다 단순한 아키텍처를 사용하여 256×256 사이즈의 이미지를 사진처럼 사실적인 디테일과 64배 더 많은 픽셀로 생성합니다.
3. Stacked Generative Adversarial Networks
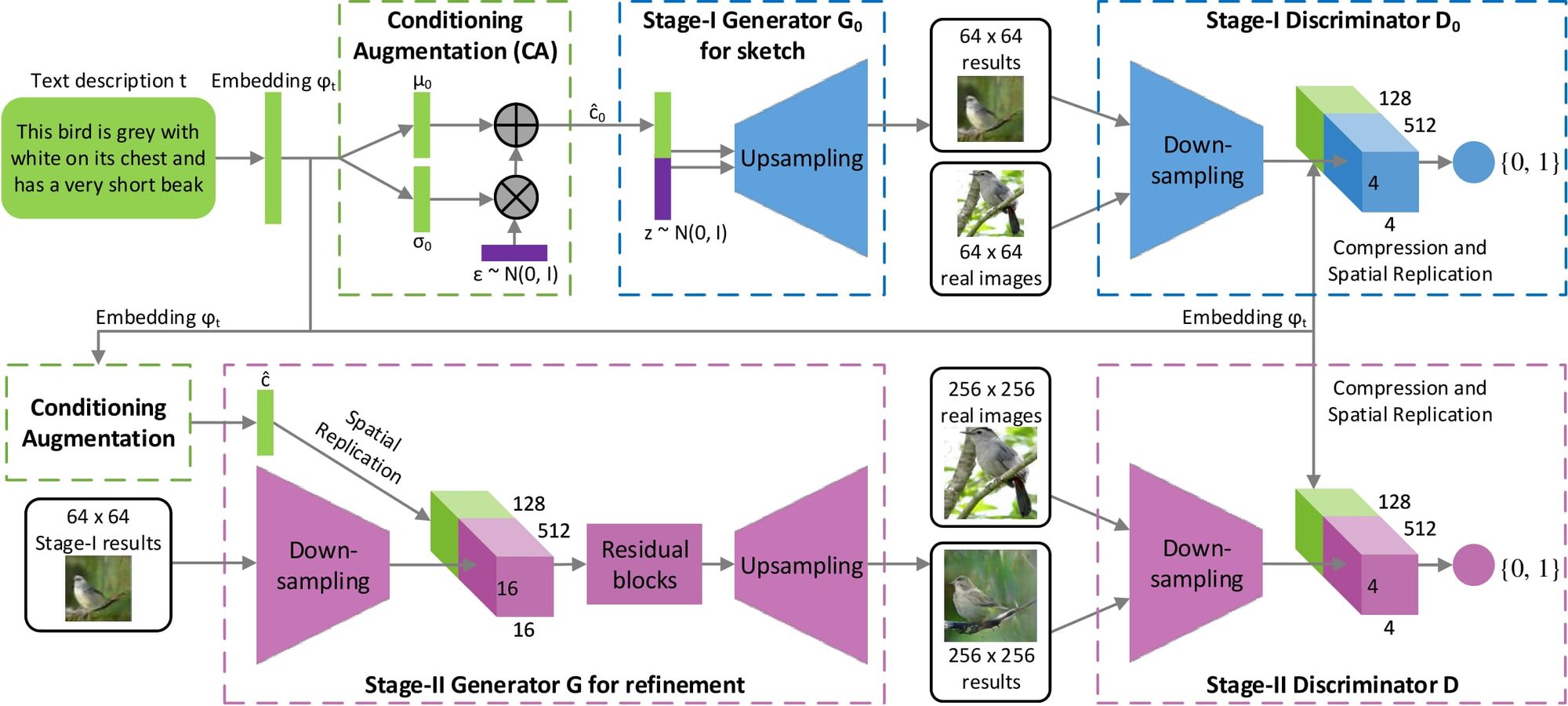
•
Stage-I GAN: 주어진 텍스트 설명에 따라 조정된 객체의 원시 모양과 기본 색상을 스케치하고 랜덤 노이즈 벡터로부터 배경 레이아웃을 그려 저해상도 이미지를 생성합니다.
•
Stage-II GAN: Stage-I에서 저해상도 이미지의 결함을 수정하고 텍스트 설명을 다시 읽어 객체의 디테일을 완성하여 고해상도의 실제같은 사진 이미지를 생성합니다.
3.1. 준비과정

여기서 x는 실제 데이터 분포 pdata의 실제 이미지이고 z는 분포 pz(예: 균일 또는 가우스 분포)에서 샘플링된 노이즈 벡터입니다.
조건부 GAN[7, 19]은 생성자와 판별자 모두, 추가 조건부 변수 c를 받아, G(z,c)와 D(x,c)를 생성하는 GAN의 확장판입니다. 이 공식을 통해 G는 조건부 변수 c에 적합한 이미지를 생성할 수 있습니다.
3.2. Conditioning Augmentation (조건부 증강)

3.3. Stage-I GAN
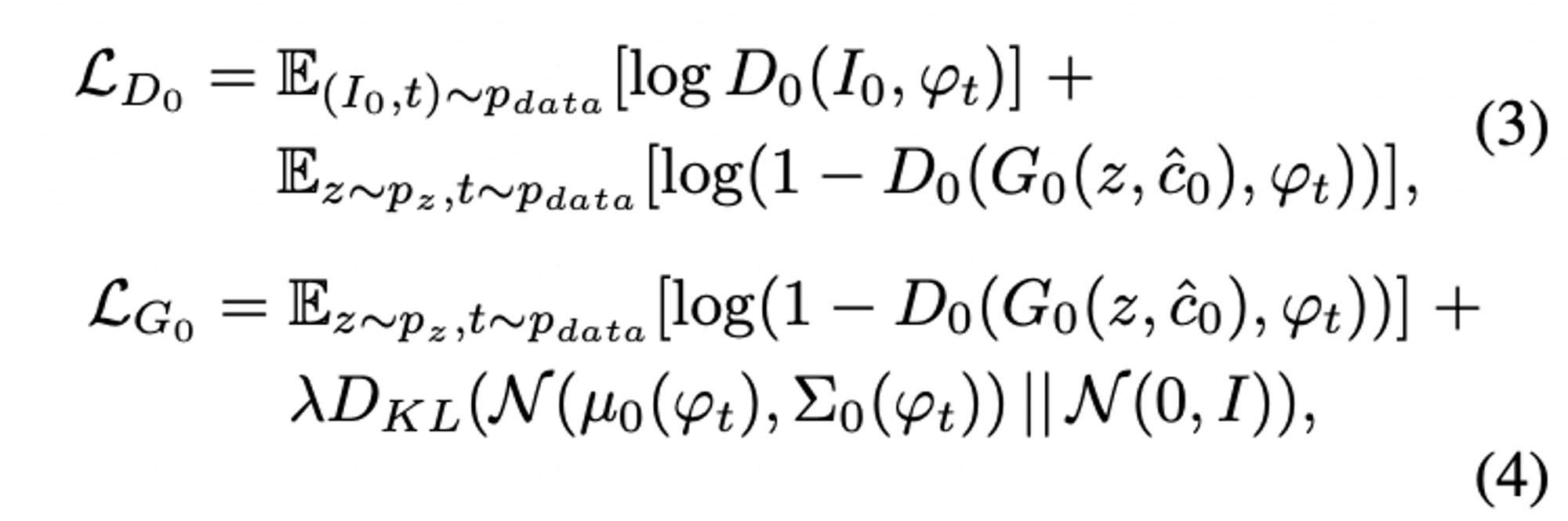
Model Architecture (모델 구조)
생성자 G0의 경우, 텍스트 조건부 변수인 c^0를 얻기 위해, 텍스트 임베딩 φt를 먼저 fully connected layer(완전 연결층)에 공급하여, 가우스 분포인 N(µ(φt),Σ(φt))을 얻기 위해, 0μ0과 0σ0(0σ0는 Σ0Σ0의 대각선에 있는 값)을 생성합니다. 그런 다음 c^0를 가우스 분포로부터 샘플링합니다. 우리의 Ng차원의 조건부 벡터인 c^0는 c^0=μ0+σ0⊙ϵ 식과 같이 계산됩니다 (여기에서 ⊙⊙은 element-wise multiplication, 아다마르 곱이다, ϵ ~ (0,)N(0,I)). 그 다음, c^0를 Nz차원의 노이즈 벡터와 연결하여 일련의 up-sampling 블럭들에 의해 0W0×H0 사이즈의 이미지를 생성해냅니다.
판별자 D0의 경우, 텍스트 임베딩 φt를 먼저 완전 연결층을 사용하는 Nd차원으로 압축하여 평평하게 펴줍니다. 그런 다음 공간적으로 복제된 Md×Md×Nd 차원의 텐서 형태로 만듭니다. 한편, 이미지는 Md×Md 공간 차원이 될 때까지 일련의 down-sampling 블록들을 거쳐 공급됩니다. 그런 다음 이미지 필터 맵이 채널의 차원을 따라 텍스트 텐서와 연결됩니다. 출력된 텐서는 이미지와 텍스트 전체의 특징을 함께 학습하기 위해 1×11×1 컨볼루션 층에 추가로 공급됩니다. 마지막으로, 하나의 노드가 있는 완전 연결층을 사용하여 decision score(의사 결정 점수)를 생성합니다.
3.4. Stage-II GAN
저해상도 결과인 0=0(,^0)s0=G0(z,c^0)와 가우스 잠재 변수 c^에 따라 조건화하면, Stage-II GAN의 판별자 D와 생성자 G는 교대로 공식(5)의 LD를 최대화, 공식(6)의 LG를 최소화하면서 훈련됩니다.
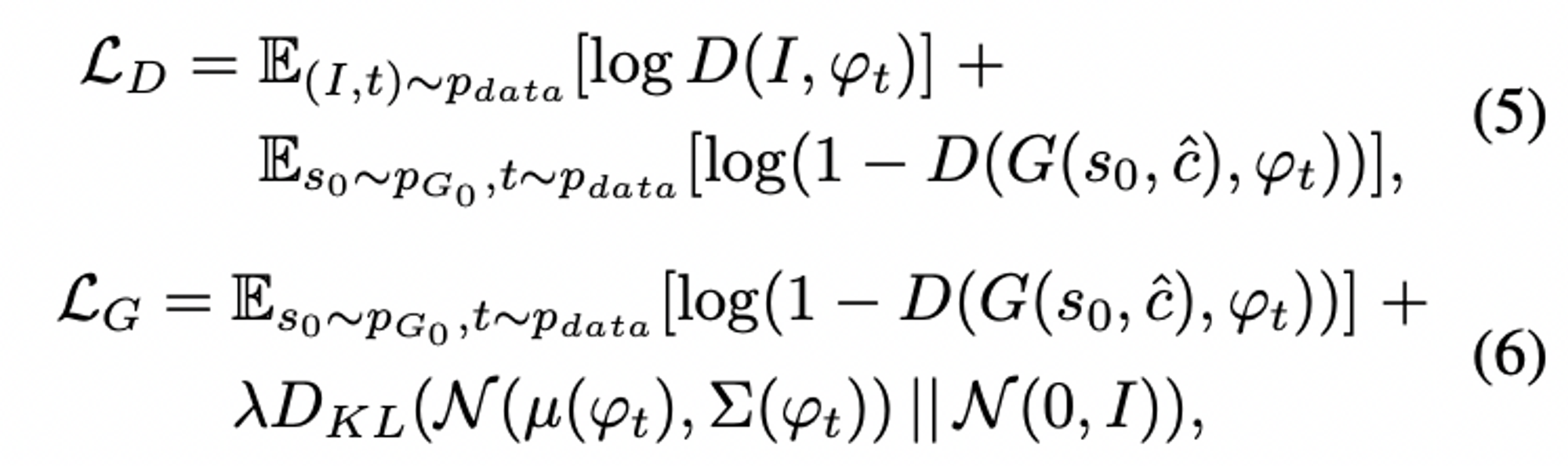
•
Model Architecture (모델 구조)
우리는 residual blocks(잔여 블록)을 추가한 인코더-디코더 네트워크로 Stage-II 생성자를 설계했습니다 [9]. 이전 단계와 마찬가지로 텍스트 임베딩 φt를 사용하여 Ng 차원의 텍스트 조건부 벡터 c^를 생성하고, 이를 공간적으로 복제하여 Mg×Mg×Ng 차원의 텐서를 형성합니다. 한편, Stage-I GAN에 의해 생성된 Stage-I 결과 s0는 Mg×Mg 공간 사이즈를 가질 때까지 여러 down-sampling 블록(즉, 인코더)으로 공급됩니다. 이미지 특징과 텍스트 특징은 채널 차원에 맞춰 연결됩니다. 텍스트 특징과 짝을 이루게 된 인코딩된 이미지 특징은, 이미지 및 텍스트 특징에 걸쳐 multi-modal representations(다양한 형태의 표현)을 학습하도록 설계된, 여러 개의 잔여 블록으로 제공됩니다. 마지막으로 일련의 up-sampling 층(즉, 디코더)를 사용하여 W×H 크기의 고해상도 이미지를 생성합니다. 이러한 생성자는 입력된 이미지의 결함을 수정하는 동시에 더 많은 세부 정보를 추가하여 사실적인 고해상도 이미지를 생성할 수 있습니다.
판별자의 경우, 이 두 번째 단계에서 이미지 크기가 더 크기 때문에 다운샘플링 블록만 추가한 Stage-I 판별자와 구조가 유사합니다. vanilla 판별자를 사용하는 대신, GAN이 이미지와 조건부 텍스트 사이의 더 나은 정렬을 학습하도록 명시적으로 강제하기 위해, 우리는 두 단계 모두에 대해 Reed et al. [26]이 제안한 matching-aware(매칭 인식) 판별자를 채택했습니다. 학습 중에 판별자는 실제 이미지와 해당 텍스트 설명을 양의 샘플 쌍으로 사용하는 반면 음의 샘플 쌍은 두 개의 그룹으로 구성됩니다. 첫 번째는 매칭된 텍스트 임베딩이 일치하지 않는 실제 이미지이고, 두 번째는 해당 텍스트 임베딩이 일치하는 합성 이미지입니다.
3.5. Implementation details (구현 세부정보)
4. 실험 및 평가
4.1. 데이터셋과 평가지표
•
Evaluation metrics (평가지표)
생성 모델(예: GAN)의 성능을 평가하는 것은 어렵습니다. 우리는 정량적 평가를 위해 최근에 제안된 수치 평가 접근법 "inception score(인셉션 점수)"[29]를 선택했습니다.

인셉션 점수는 샘플의 시각적 품질에 대한 인간의 인식과 잘 상관관계가 있는 것으로 나타났지만 [29], 생성된 이미지가 주어진 텍스트 설명에 따라 잘 생성됐는지 여부는 반영할 수 없습니다. 따라서 사람이 직접 눈으로도 평가를 합니다. CUB 및 Oxford-102 테스트셋의 각 클래스에 대해 50개의 텍스트 설명을 무작위로 선택합니다. COCO 데이터셋의 경우 유효성 검사셋에서 4만개의 텍스트 설명을 임의로 선택합니다. 각 문장에 대해 모델별로 5개의 이미지가 생성됩니다. 동일한 텍스트 설명이 주어진 경우, 10명의 사용자(저자 제외)에게 서로 다른 방법으로 결과에 순위를 매기도록 합니다. 비교된 모든 방법을 평가하기 위해, 사용자들이 평균 순위를 계산합니다.
4.2. 정성적 및 정량적 결과



Figure 3과 같이, GAN-INT-CLS[26]에서 생성된 64×64 샘플은 새의 일반적인 모양과 색상만 반영할 수 있습니다. 이러한 결과는 대부분의 경우 생생한 부분(예: 부리와 다리)과 설득력 있는 디테일이 부족하여 충분히 사실적이지도 않고 해상도가 높지 않습니다. GAWWN[24]은 위치 제약에 대한 추가 조건 변수를 사용했지만, CUB 데이터셋에서 여전히 약간 낮은 더 나은 인셉션 점수를 기록했습니다. Figure 3에서 보이는 것처럼, GAN-INT-CLS보다는 더 상세한 고해상도 영상을 생성하는 것을 알 수 있습니다. 그러나, GAWWN 논문의 저자들이 언급한 바와 같이, GAWWN은 텍스트 설명만을 가지고서는 그럴듯한 이미지를 생성하지 못합니다. 이에 비해 StackGAN은 텍스트 설명만을 가지고도 256×256의 사실적인 이미지를 생성할 수 있습니다.

Figure 5는 StackGAN에서 생성된 Stage-I 및 Stage-II 이미지의 몇 가지 예를 보여줍니다. 그림 5의 첫 번째 행에서 볼 수 있듯이, 대부분의 경우, Stage-I GAN은 텍스트 설명에 따라 개체의 대략적인 형태와 색상을 그려낼 수 있습니다. 그러나 Stage-I 이미지는 특히 전경 객체의 경우 다양한 결함과 누락된 세부 정보로 인해 일반적으로 흐릿합니다. 두 번째 행에서 볼 수 있듯이 Stage-II GAN은 보다 설득력 있는 디테일로 4배 더 높은 해상도의 이미지를 생성하여 해당 텍스트 설명을 더 잘 반영합니다. Stage-I GAN이 그럴듯한 모양과 색상을 생성한다면, Stage-II GAN은 생성될 이미지의 세부 사항을 완료합니다. 예를 들어, Figure 5의 첫 번째 열에서, Stage-II GAN은 만족스러운 결과로, 꼬리와 다리에 대한 세부 사항뿐만 아니라 텍스트에 설명된 짧은 부리와 흰색도 묘사하는 데 초점을 맞춥니다. 다른 모든 예시에서 Stage-II 이미지에 다양한 세부 정보가 추가되는 것을 확인할 수 있습니다. 다른 많은 경우, Stage-II GAN은 텍스트 설명을 한번 더 다시 처리하여 Stage-I 결과의 결함을 수정할 수 있습니다. 예를 들어, 5번째 열의 Stage-I 이미지에는 텍스트에 설명된 갈색계열의 머리가 아닌 파란색이 있지만 이 결점은 Stage-II GAN에 의해 수정됩니다. 일부 극단적인 경우(예: Figure 5의 7번째 열)에서, 심지어 스테이지-I GAN이 그럴듯한 모양을 그리는데 실패하더라도, 스테이지-II GAN은 합리적인 객체를 생성할 수 있습니다. 또한 StackGAN이 Stage-I 이미지로부터 배경 정보만을 전송하고 Stage-II에서 이를 더 높은 해상도로, 그리고 더 사실적으로, 미세 조정하는 것을 관측할 수 있습니다.

여기서 눈여겨봐야할 점은 StackGAN이 단순히 학습하는 샘플을 암기하는 것이 아니라 복잡한 [언어-이미지] 관계를 포착함으로써 좋은 결과를 얻는다는 것입니다. 우리는 StackGAN의 Stage-II 식별자 �D에 의해 생성된 이미지와 모든 학습된 이미지에서 시각적 특징을 추출했습니다. 그리고 생성된 각 이미지에 대해 훈련셋으로부터 최근접 이웃 탐색을 통해 유사한 이미지를 검색할 수 있습니다. 검색된 이미지를 육안으로 살펴보면(Figure 6 참조), 생성된 이미지가 학습 샘플과 유사한 특성을 가지지만 본질적으로 다르다는 결론을 내릴 수 있습니다.
4.3. Component analysis (성분분석)
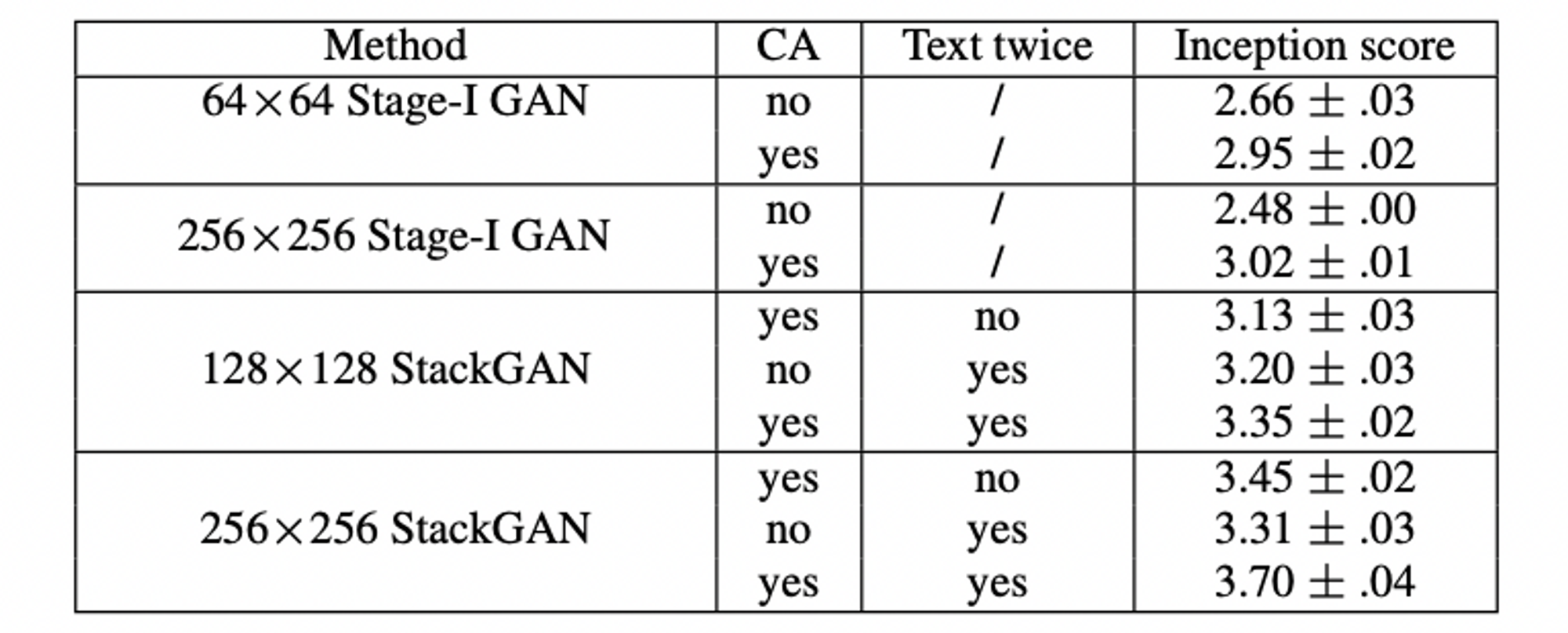

Table 2의 처음 4개 행에서 볼 수 있듯이, Stage-I GAN을 직접 사용하여 이미지를 생성하면 인셉션 점수가 크게 감소합니다. 이러한 성능 저하는 Figure 7의 결과를 통해 잘 드러날 수 있습니다. Figure 7의 첫 번째 행에서 볼 수 있듯이, Stage-I GAN은 Conditioning Augmentation (CA)을 사용하지 않고서는 그럴싸한 256×256 샘플을 생성하지 못합니다. CA를 포함한 Stage-I GAN은 보다 다양한 256×256 샘플을 생성할 수 있지만, 이러한 샘플은 StackGAN에서 생성한 샘플만큼 현실적이지 않습니다. 이는 이 논문에서 제안하는 적층 구조의 필요성을 보여주는 사례입니다. 또한 출력 해상도를 256×256에서 128×128로 낮추면 인셉션 점수가 3.70에서 3.35로 낮아집니다. 모든 영상은 인셉션 점수를 계산하기 전에 299×299로 스케일링됩니다. 그리고 Stack-GAN이 더 많은 정보를 추가하지 않고 이미지 크기만 늘리면 다른 해상도의 샘플에 대한 인셉션 점수는 동일하게 유지됩니다. 따라서 인셉션 점수가 128×128 StackGAN에서 낮아지는 현상은 256×256 StackGAN이 더 큰 이미지에 더 많은 세부 정보를 추가한다는 것을 의미합니다. 256×256 StackGAN의 경우, 텍스트를 Stage-I에만 입력하면("텍스트 두 번 없음"으로 표시됨) 인셉션 점수가 3.70에서 3.45로 감소합니다. 이는 Stage-II에서 텍스트 설명을 다시 처리하면 Stage-I 결과를 개선하는 데 도움이 된다는 것을 나타냅니다. 128×128 StackGAN 모델의 결과에서도 동일한 결론을 도출할 수 있습니다.
•
Conditioning Augmentation (조건부 증강)
우리는 또한 제안된 조건부 증강(CA)의 효과도 조사했습니다. StackGAN 256×256(Table 2에서 "CA 없음"으로 표시됨)에서 조건부 증강(CA)을 제거하면 인셉션 점수가 3.70에서 3.31로 낮아집니다. 그리고 역시 Figure 7에서 CA를 사용하는 256×256 Stage-I GAN(및 StackGAN)이 동일한 텍스트 임베딩에서 서로 다른 포즈와 관점을 가진 새들을 생성할 수 있음을 확인할 수 있습니다. 반대로, CA를 사용하지 않을 경우, 256×256 Stage-I GAN에 의해 생성된 샘플은 GAN의 불안정한 훈련 동력으로 인해 무의미한 이미지로 저하됩니다. 결과적으로, 제안된 Conditioning Augmentation (조건부 증강)은 조건부 GAN 훈련을 안정시키고 잠재 매니폴드를 따라 미세한 변화에도 안정적일 수 있는 능력 때문에 생성된 샘플의 다양성을 향상시킵니다.
•
Sentence embedding interpolation (문장 삽입 보간)

5. 결론
[1] M. Arjovsky and L. Bottou. Towards principled methods for training generative adversarial networks. In ICLR, 2017. 2