감정Ai(14)- 이미지 확대하기

우리는 데이터 전처리를 조금 해 볼 거예요
먼저 해야 할 것은 데이터들을 입력과 출력으로 나누는 것이에요

입력은 대문자 X로, 출력은 소문자 y로 부를 거예요
그럼 먼저, 'X = facialexpression_df'라고 해줍시다 그리고 ' pixels' 열을 가져와야 하고
이게 입력이 될 거예요 본질적으로 사진이죠
그다음 단계는 facialexpression_df를 가져와서 'emotion'열을 뽑을 거예요
이를 위해 to_categorical 을 해줄 건데 기본적으로 y 열을 줄 것이고
가지고 있는 각각의 모든 카테고리가 되겠죠
계속해서 실제로 실행시켜보기 전에2개로 나눠 볼까요?
자, 이제 지정된 facialexpression_df[' pixels'] 만 있고 to_categorical은 y가 되었죠
그럼 가서 X와 y를 확인해 봅시다
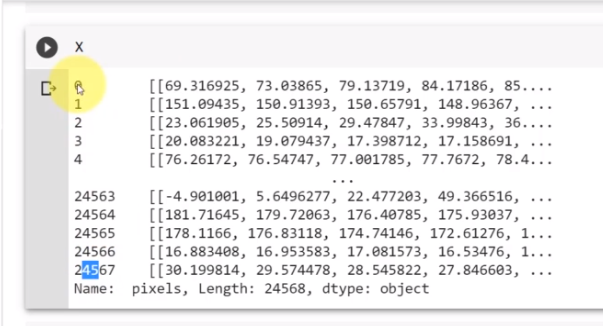
여기에 X를 입력하면, 각기 다른 모든 사진들을 볼 수 있을 거예요
예를 들어, 여기에 24,000개의 사진들이 있고 각 행들은 사진이에요
그리고 실제 픽셀들은 여기 또 다른 배열 안에 적혀 있어요

예를 들어, X[0]을 확인해 보면, 첫 번째 이미지를 나타낼 거예요
여길 보면 이미지의 첫 번째 행을 볼 수 있고, 그 뒤에
그다음 행이 있고 그러고 나서 세 번째 행이 있고 이런 식으로 있죠
이제 이걸 조금 조정해야 하는데 어떻게 하는지 보여드릴게요
np.stack을 적용해 볼 수 있고 여기에 있는 문제를 해결해 줄 거예요
계속해서 출력을 확인해 봅시다
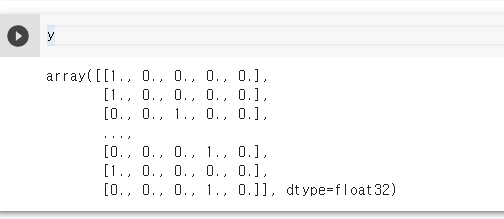
y를 입력하고 shift + enter 하면 자, 나왔네요
기본적으로, 'from keras.utils import to_categorical'을 해 주었고
기본적으로 여기에서 해 볼 것은 만약 class가 첫 번째 class
즉, [1., 0., 0., 0., 0.], 두 번째 이미지는 [1., 0., 0., 0., 0.], 세 번째 이미지는
[0., 0., 1., 0., 0.] .. 이런 식으로 해 주는 거예요 그리고 이게 to_categorical로 바꿔주는 이유예요
(to_categorical은 Keras의 유틸리티 함수로, 정수형 레이블을 원-핫 인코딩(one-hot encoding) 형태로 변환해주는 역할)
다음 단계에서는 {X = np.stack}이라고 해줄 것이고 여기서 해줄 것은 이미지 모양을 (24568, 96, 96, 1)
맞춰주는 거예요
즉, 총 24,000개의 이미지를 가질 거고 각각의 이미지는 96 x 96 픽셀에 1이 될 거라는 것이죠
여기서 1이라고 해 주는건, 우리가 흑백사진을 이용하기 때문에 1개의 컬러 채널만 있다고
표시해 주는 거예요

나왔네요
자, 이제 24,568개의 이미지가 있고 각각의 이미지는 96 x 96 픽셀이에요
그리고 출력은 똑같이 대략 24,000개가 나왔고
여길 보면 총 5개의 열이 있다고 알려주죠 기본적으로 각각의 class를 1로 표시하는
거예요
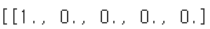
그러니까 예를 들어, 첫 번째 행의 경우 첫 번째 카테고리, 즉 첫 번째 감정에 포함되어있고
계속해서 이런 식으로 표현한 것이죠
그리고 여기에서는 기본적으로 각각의 이미지마다 한개의 감정만 가지고 있는 것을 알아주세요
그래서 2개의 감정을 가지고 있는 경우는 없을 거예요 예를 들어, 분노와 혐오
[1., 0., 0., 1., 0.] 이렇게 둘 다 가질 수는 없어요
오직 하나의 감정을 나타내는 한 개의 '1'을 제외하고서는 모두 0이어야 해야 한다는 거예요
자, 이렇게 한 다음에, 나아가서 이제 Scikit learn에서 나온 train_test_split을 적용해서
데이터를 학습, 테스트, 검증으로 나누어 볼 수 있어요
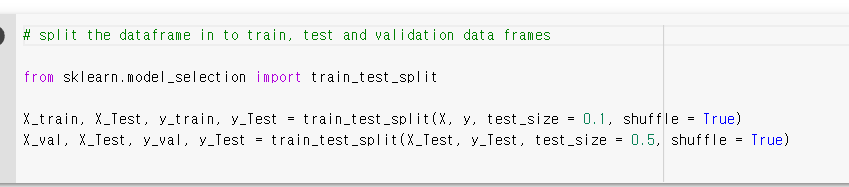
'from sklearn.model_selection import train_test_split'을 해 주고
'train_test_split'에 입력인 X를 주고 y는 출력이고 테스트 사이즈는 10%로 설정해줄 거예요
그러니까 여기에서, 90%를 학습에 10%를 테스트에 쓰도록 지정해 주는 것이죠
그다음으로 해 볼 것은 테스팅 데이터를 가지고와서 (X_test, y_test) 반절로 나누어 줄거예요
그래서 test_size를 0.5로 설정해줄 것이죠 이 말은 즉슨, 테스팅 데이터를 가지고 와서
X 테스트와 X 검증에 한번 더 나누어 주는 것이죠
이제 X_val, X_Test, y_val, y_Test가 있죠
자 shift + enter를 해 주고

여기를, 예를 들어, 0.4로 조정해줄 수도 있어요
40%가 테스팅과 validation에 60%를 트레이닝에 사용하겠다는 뜻이죠
가서 쉐입을 확인해 봅시다
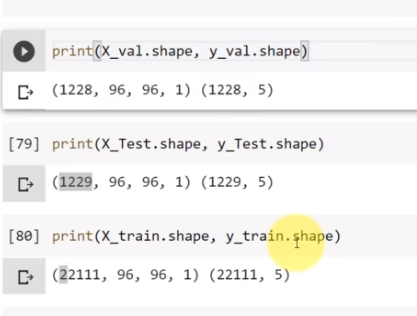
나왔네요 자, 여길 보면 (1228, 96, 96, 1)가 있죠 그리고 (1228, 5)는 검증 데이터세트에 대한 거예요
이것과 비슷하게 예를 들어, 테스팅 데이터세트를 확인하고 싶으면
X_Test와 y_Test를 적어주면 돼요
자, 이게 테스트 데이터 이고 테스트 데이터에 1,229개의 샘플들이 있죠
그리고 당연히 트레이닝 또한 확인해 볼 수 있죠 X_Train, y_Train으로 바꾸고
기본적으로 새니티 체크를 하는 거예요
대략 학습을 하는데에 22,000개의 사진들이 있고, 거의 1,200개에 테스트,샘플 1,200개를 검증에 사용하네요
훈련 데이터를 훈련(Training) 세트, 검증(Validation) 세트, 테스트(Test) 세트로 나누는 이유는 모델의 성능을 평가하고 일반화 능력(generalization)을 최대한 향상시키기 위함입니다.
훈련 세트: 훈련 세트는 모델을 학습시키는 데 사용됩니다. 즉, 훈련 세트에 있는 데이터를 사용하여 모델의 가중치와 편향을 업데이트합니다.
검증 세트: 검증 세트는 모델의 성능을 평가하고, 하이퍼파라미터(hyperparameter)를 조정하는 데 사용됩니다. 검증 세트를 사용하여 학습 중인 모델의 성능을 검증하고, 이를 기반으로 하이퍼파라미터를 튜닝하여 모델의 일반화 능력을 높입니다. 검증 세트를 사용하면 훈련 데이터에 과적합(overfitting)되지 않도록 모델을 조정할 수 있습니다.
테스트 세트: 테스트 세트는 모델의 최종 성능을 평가하는 데 사용됩니다. 테스트 세트는 모델의 학습과 하이퍼파라미터 튜닝에 전혀 사용되지 않으며, 모델이 새로운 데이터에 얼마나 잘 일반화되는지 평가하는 데 사용됩니다. 테스트 세트를 사용해 모델의 실제 성능을 확인할 수 있습니다.
훈련, 검증, 테스트 세트를 나누는 것은 모델이 훈련 데이터에 과적합되지 않고, 새로운 데이터에 대해 좋은 예측 성능을 보이도록 하기 위한 중요한 전략입니다. 이를 통해 모델의 일반화 능력을 최대한 향상시키고, 실제 환경에서의 성능을 평가할 수 있습니다.
계속해서 이미지를 표준화 시켜봅시다

이제 이걸 255로 나누어 줄 거고 기억해 보시면 이전에 했던 것과 그대로 똑같죠
255로 나누어 주면 이미지를 표준화 시켰어요

예를 들어, 지금 X_Train을 확인해 보면
픽셀 숫자들이 0과 1사이가 되도록 잘 작동된 것을 보실 수 있죠
그리고 여기에서 해 볼 것은 더 많은 이미지들을 만드는 거예요
이미지 증강을 조금 하고 싶어요
이를 위해서, 조금 다른 방법을 써볼 것인데 왜냐하면 지난번을 기억해 보시면
이미지 증강을 수동으로 직접 했었죠
직접 이미지를 가져와서 직접 좌우 반전시키고 직접 상하 반전시키고
직접 밝기를 올렸어야 했었죠
여러분이 기억하시도록 위로 올라가 보면.. 여기 부분에서 데이터 증강을 해 보았죠
https://parkit.tistory.com/102
여기 위에 있네요 기억해 보시면, 우린 수동으로 직접 해야 했었어요
데이터 프레임 복사본을 만들고, 1.5~2 사이의 값을 곱해줬었어요
이미지의 밝기를 올리려고요 이미지를 가지고와서
뒤집어 보기도 했고요 이를 위해 '96. - float(x)'도 해 주었었죠
사실 조금 머리아팠죠

그래서, 여기에서는 ImageDataGenerator라는 것을 사용해 볼 거예요
증강을 하는데에 있어서 훨씬 더 쉽도록 트릭을 써볼 거예요
자, 여기에 ImageDataGenerator를 부르고 회전 각도를 15로
{width_shift_range = 0.1, height_shift_range = 0.1,shear_range = 0.1}으로
지정해 주고
그리고 zoom_range = 0.1이 되도록 해 볼 수 있죠
horizontal_flip = True로 해줄 수 있고
그리고 기본적으로 여기에서 하려고 하는 것은 다양한 종류의 증강을 해 보려고 하는 것이예요
이게 조금 헷갈리기 들릴 수도 있다는 것을 이해해요 이게 여러분들을 위해 간단한 미니 과제를 넣은
이유이고요
먼저 shift + enter부터 해줄게요
여러분들은 가셔서 적어도 2개 이상의 추가적인 데이터 증강을 해 보시면됩니다
그래서 여러분들은 외부 조사를 조금 해 보고 각각의 증강 방식들과
이 값들이 무엇을 의미하는지에 대해 리뷰해 보세요
여러분들이 해야 할 것은
여기에 두개의 추가적인 증강 기술을 추가해 보는 것이죠
자, 예를 들어 horizontal_flip 대신에 vertical_flip을 사용해 볼 수 있고 혹은, 예를 들어, 밝기를 바꿔볼 수도 있죠
https://keras.io/api/preprocessing/image/
먼저, 여기 이 링크를 클릭해서 Keras 문서를 확인해 보면
Keras에 있는 이미지 증강에 대한 모든 내용과 정보들을 찾아볼 수있어요
여기 아래로 스크롤을 내려보면, ImageDataGenerator class를 찾을 거예요
그리고 여기에 사용할 수 있는 모든 이미지 증강 방법이 있죠
예를 들어, rotation_range를 사용해 볼 수 있고
brightness_range를 바꿔볼 수도 있죠
좌우 반전시킬 수도 있고 상하 반전 시킬 수도 있어요
정말 다양한 방법들이 여기에 있답니다
예를 들어, zoom_range 이런 것도 있고요

그리고 여기에 정말 다양한 세부 내용이 있다는 것을 알아주세요
예를 들어, 여기 brightness_range를 보면 더 어둡게 할건지, 밝게 이미지를 바꿀건지 정도를 정할 수 있고요
아니면 예를 들어, zoom_range를 하고 싶으시다면
확대/축소 범위가 있죠 이미지를 줌하도록 설정할 수 있고
얼마나 확대할건지 이런 식으로 정할 수 있어요
만약 좌우 반전을 시키고 싶다면
이건 boolean 타입이에요 기본적으로 좌우반전을 시킬지 말지를 정하는 것이죠
만약 상하반전을 시키고 싶으면 이것도 boolean인데 임의로 이미지를 상하로 뒤집는 것이죠
크기도 조정할 수 있고
다양한 증강 방법들을 해 볼 수 있죠

다시 돌아와서
여길 보면 간단한걸 골랐어요
먼저, 좌우반전을 하도록 선택할 것이고
상하반전을 추가해 볼 것이고
그리고 밝기 정도도 추가할 거예요
먼저 vertical_flip을 넣어주고'vertical_flip = True'를 적어서 상하반전을 해줄 거예요
방금 상하 반전을 추가해 주었고 밝기 정도도 추가해줄 수 있죠
brightness_range =를 적어주고 그리고 여기에서 정도를 정해줄 거예요
예를 들어, [1.1, 1.5] 사이가 되도록 해줄 수 있죠
이렇게 되면 이미지 밝기가 밝아질 거예요