감정Ai(1)-라이브러리와 데이터 집합 가져오기

첫 번째 단계는, 컴퓨터 드라이브를 마운트 하는 것이에요
간단하게 말해서
저는 두 모델을 위해 필요한 모든 이미지를 구글 드라이브에 올려놨고
제가 하려는 건 여기 제 노트북이 구글 드라이브에 저장된 이미지와 데이터에
접근할 수 있도록 해주는 것이에요

그냥 'from google.colab' 우리는 'import drive' 할 거고
그다음, 'drive.mount'
그다음, 여기에서 '/content/drive'를 적어주면 됩니다
자, shift+enter를 누르면, 여기 드라이브가 이미 준비되어 있다고 알려주죠

그다음 단계는 현재 디렉터리를 지정해 주는 것인데요
그리고 이게 제 현재 디렉터리가 될 거예요
'Modern AI Portfolio Builder'가 있고, 그다음 'Emotion AI'로 지정해 줬어요
이렇게 모든 데이터를 포함해 주었고
또한, 이 위치에 학습시킨 모델을 저장할 수도 있어요

그리고 여길 보면, 모든 필요한 패키지와 라이브러리을 불러왔어요
정말 많은 라이브러리가 있는데
가장 중요한 건, Tensorflow 2.0와 Keras API를 이용해서
모델을 구축하고 학습시킬 거라는 점이에요
여러분도 보이시겠지만, 정말 많은 Tensorflow 관련 라이브러리를 사용할 거예요
예를 들어, 'EarlyStopping'이나 'ModelCheckpoint'을 불러올 것이고
입출력에 관해서는 걱정하지 마세요
본격적으로 프로젝트를 시작해서 실제로 다루게 되면 자세히 알려드릴
거예요
이게 Tensorflow 파트가 될 것이고
그리고 여기, pandas를 pd라고 불러올 건데, pandas는 주로 데이터 프레임 조작에 쓰여요
그다음, numpy도 np라고 불러올 거고 numpy는 수치 해석하는 데에 쓰여요
운영 체제를 위해서 os도 불러올 거고요
PIL 또는 pillow라고 불리는 걸 불러올 건데
이미지 다루는 것을 도와줄 거예요
또, 주로 데이터 시각화에 쓰이는 seaborn을 sns라고 불러올 것이고요
자, 그래서 첫 번째로 해야 하는 것은 데이터를 로드하는 것이에요

주요 얼굴 포인트 데이터를 로드해 볼 거고 데이터는 이 위치에 있어요 '/content/drive/My Drive/Colab Notebooks/Modern AI Portfolio Builder/Emotion AI /그다음, 우리 데이터'data.csv'가 있죠
그냥 data.csv만 지정해 줘도 돼요 이미 우리가 앞에서
현재 디렉터리를 'Emotion AI'까지 지정해 줬기 때문이죠
사실 전체 경로를 모두 지정해 줄 필요는 없지만
아무튼 여기서는 해줬어요
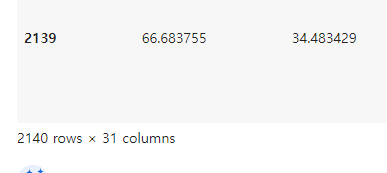
그럼 이제 필요한 모든 데이터가 'keyfacial_df'에 있는 거예요
모든 정보를 담고 있는 제 데이터 프레임인 거죠
계속해서 확인해 봅시다
무슨 일이 일어나는지 보자고요
그리고 항상 마지막에는
이것도 꽤 중요한 점인데
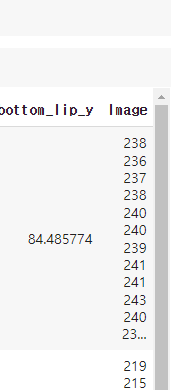
이렇게 오른쪽으로 넘겨보면 마지막 열이 있죠
이것은 실제 이미지의 실제 픽셀 값이에요
이전에 이미지 다뤄볼 때를 기억해 보시면
모든 이미지는 기본적으로 픽셀로 이루어져 있고, 이 픽셀은 0부터 255까지 있죠
0은 검은색 픽셀이고, 255는 하얀색 픽셀을 나타내요
이 사이의 값은 모두 회색 스케일, 회색 값이고요

여기 모든 주요 포인트를 위한 x, y 좌표값이 있고요
마지막 열은 실제 사진의 실제 픽셀 값을 가지고 있는 것이죠
계속해서, info()를 적용해서 더 많은 정보를 가져와 봅시다

각기 다른 이름의 열이 있고요
왼쪽 눈, 그다음 오른쪽 눈, 그다음 왼쪽 눈 안쪽 끝
왼쪽 눈 바깥쪽 끝
그다음 오른쪽 눈 안쪽 끝이 있고
이런 식으로 있죠
그리고 좋은 점은 Null 특성이 하나도 없는 것 같네요
전체 모두 2140개의 Non-Null 특성을 가지고 있고요
그리고 데이터 타입은 이미지를 제외하고 모두 float64이네요

그리고 이건 제 데이터 크기예요
그럼 이제 데이터 프레임에 혹시 null 값이 있는지 확인해 봅시다
이를 위해 'keyfacial_df'을 적어줘서 제 데이터 프레임으로 가서
null 값이 있는지 찾아보라고 해주고
찾은 모든 null 값 개수를 알려달라고 해줄게요

이 말은 null 값이 하나도 없다는 것을 의미해요
그다음으로, 이미지 열의 shape을 확인해 봅시다
keyfacial_df라고 해주고,
열을 확인해 볼 건데, 이 경우엔 'Image'이고 이에 대한 shape을 얻어보면

'2140'가 있는 것을 찾을 수 있죠
그러면, 제가 모든 픽셀 값을 담고 있는 하나의 D 배열을 가지고 있는 것이죠
이제 해야 할 것은, 데이터를 reshape 하는 것이에요
저는 마지막 열이 이미지 형태로 shape을 바꿔줄 거예요
96 x 96 픽셀 형태로 만들 것이죠
그래서 해야 할 일은 lambda 함수를 이렇게 써줄 거예요
"keyfacial_df에 가서 'Image'라는열에 간 다음.."
여기 위로 가보시면 'Image' 열이 있는
것을 보실 수 있죠
대문자 i인 것을 주의하시고, 이걸 가져와서

lambda 함수를 적용해 줄 거예요 기본적으로 lambda 함수는 x를
열에 있는 모든 요소을 가져올 것이고, 저는 그걸 numpy 배열로 바꿀 거예요
그러니까, 실제 값, 즉 x 값을 가져올 것이고 그리고 이 x 값은 string 형태로 나타날 거예요
그래서 여기에서 저는 이 string 포맷을 가져온 후에, 거기 있는 모든 value을 띄어쓰기를 기준으로
나눠줄 거예요
데이터 타입은 int(integer)로 'seperator'는 띄어쓰기(' ')로 해줄 거예요
하나를 예로 가져와 보자면

여기에 이 값 사이가 띄어져 있다는 것을 알아주세요
이 각각의 숫자을 가져와서 string 포맷에서 numpy 포맷으로
바꿔줄 겁니다
그다음에는, 그것을 가져와서 96 x 96 픽셀로 실제로 reshape 해줄
거예요
이다음에는, 이미지 열에 numpy 배열 포맷의 개조된 데이터로 바꿔줄
거예요
그렇게 하면 완벽해요
이후에 모델을 학습시킬 때 사용할 수 있게 되는 거예요
그럼 계속해서 샘플 이미지로
실제로 확인을 해봅시다
'keyfacial_df'로
가서 실제 'Image'에 간 다음
첫 번째 행을 확인해 줄게요
예를 들어, 0 번째 행을 확인해 줄게요 그리고 이에 대한 shape도 확인할 거예요

나왔네요
이제는 96 x 96 픽셀로 바뀌었고
그럼 이제 이 데이터를 가지고 시각화하거나 이미지 확대,
혹은 AI 모델 학습 등을 할 준비가 된 거예요
이제는 미니 과제를 할 시간이네요
여러분은 이제 'right_eye_center_x'의 평균과 최솟값,
최댓값을 구해보세요

일단 데이터 프레임을 가져올 거예요, 'keyfacial...'
참고로,crtl+space 키를 누르면 자동으로 우릴 위해 완성시켜 줘요
'keyfacial_df.describe()'을 적어주고, describe()는 데이터를 통계적으로 요약해서
저에게 알려줘요

여길 보면 모든 열이 있고, 열마다 몇 개의 샘플이 있는지 알려주는
'count'가 있고
여기 'mean' 값도 있죠
모든 열의 평균 값이고
그리고 표준 편차도 있어요, 중앙 값의 분산도를 나타내죠
여길 보면 최솟값이 있고
여기는 최댓값이 있죠
그리고 여기에 25 백분위, 50 백분위, 75 백분위 수도 있답니다
기본적으로 문제는 굉장히 단순했어요
'right_eye_center_x'의 최소 최댓값과 평균을
구하라는 문제였는데
확인해 보면
여기에 right_eye_center_x가 있고
평균 값을 구하기 위해 보면, 29.6가 되겠네요
최솟값은 18.9가 될 거고, 최댓값은 42.49가
되겠네요